本文最后更新于 2026-06-03T22:37:25+08:00
0. 开始的开始
一直想做一个图书漂流软件,最近入手(入坑)了微信小程序,添加图书时需要用到isbn查询书籍信息的API(不用也可以,但用户会非常麻烦,强迫症晚期的我又跳入了isbn查询API的坑),但发现别人的API都很贵,豆瓣也收回了API的使用权,估计是要收费了。
所以,与其在坑里苦苦挣扎,不如。。。。再挖一个更大的坑,自己做一个。。。
1. 开始
首先打算用python写个爬虫(能力与知识有限,现在只能想到这个办法,如前辈们有更好的办法,请砸过来)。
搜索了几个可以用isbn查书籍信息的网站,最后还是选择了豆瓣。
豆瓣isbn查书籍信息的流程为:
- 打开豆瓣读书的首页

- 在搜索框输入isbn码

- 回车或点击小放大镜,书籍的信息出来了

本来想的很好,就这样一路闪电带火花把核心代码写了,然而,总有不尽人意的地方。就在第3步,本来打算在这里把信息给爬了,却发现爬回来是空的,也不知道什么原因(查html代码,发现有一级标签id为root,可能豆瓣设置了权限,猜的,具体原因不知道)。
2. 爬取内容
虽然人生不尽人意,但还是要走下去。在第3步的页面,点击书名或图片会出来更详细的信息。

果然,这里的信息可以爬取,要什么有什么。
2.1 获取书籍信息页面的链接地址
思路:
打开豆瓣读书首页,模拟浏览器填写isbn码,进行搜索,跳转到搜索结果页面,读取a标签href链接,即书籍信息页面的链接地址。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def isbn_search(isbn):
"""
输入:isbn
输出:豆瓣搜索结果的书籍链接
"""
browser = webdriver.PhantomJS()
browser.get("https://book.douban.com/subject_search?search_text=" + isbn + "&cat=1001")
soup = BeautifulSoup(browser.page_source, "lxml")
tags = soup.select("#root > div > div > div > div > div > div > a")
link_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", str(tags[0]))
browser.close()
return link_list[0]
|
2.2 爬取书籍详细信息
思路:
打开2.1获取的页面,找到书籍信息块代码,爬回并清洗,得到需要的信息。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| def book_info(douban_link):
"""
输入:豆瓣书籍链接
输出:书籍信息
"""
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/80.0.3987.149 Safari/537.36'}
g=requests.get(douban_link,headers=headers)
soup=BeautifulSoup(g.content,"lxml")
title = "书名: 《" + re.sub('[\f\n\r\t\v]','',re.sub('<([^>]+?)>','',str((soup.select("#wrapper > h1 > span"))[0]))) + "》"
infos = [title]
span_list = soup.findChild('div',{'id':'info'})
for item in str(span_list).split('<br/>'):
info_item = re.sub('[\f\n\r\t\v]','',re.sub('<([^>]+?)>','',item)).split(":")
info_temp = []
for info_item_item in info_item:
sprit = info_item_item.partition("/")
for sprit_item in sprit:
info_temp += sprit_item.partition("]")
temp_list = []
for temp in info_temp:
ddd=temp.strip()
if ddd != '':
temp_list.append(ddd)
else:
continue
info = temp_list[0] + ': '
for i in range(1, len(temp_list)):
info += temp_list[i]
if temp_list:
pass
else:
continue
infos.append(info)
return infos
|
3. 效果
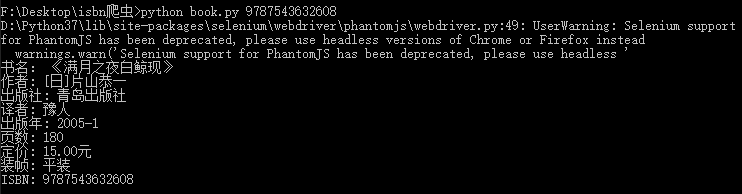
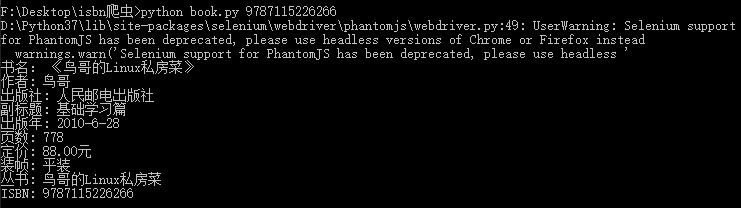
这里使用PhantomJS浏览器,但会报UserWarning,Selenium最新版不支持PhantomJS了,我用的Selenium 3.141.0,UserWarning建议使用谷歌或火狐浏览器的无头模式,但我没成功,如有大佬成功了希望交流一下。
4. 完整代码下载
isbn查询书籍详细信息
仅供学习,勿作商用,如有违反,后果自负。
不知道豆瓣有一天会不会把这个方法给ban掉。